这是一个基于Python和Cupy从零开始实现的深度学习框架
前言
目前深度学习框架各式各样,国外有大家最为熟知的Pytorch,tensorflow,mxnet,也有一些国内的PaddlePaddle(百度),OpenMMlab(商汤&港大)。这些工业级深度学习框架虽然运算速度很快,有丰富的算子,模型,优化器,数据io接口,但是里面高度封装,其背后是如何运行的对于大多数非计算机专业的同学来说比较头疼。而想要深入进行科研,学会在上述框架的基础上进行二次开发是必要的,目前CVPR顶会一些基础性研究,比如对vison for transformer的兴起,都是对基础构件的加工修改,又如一些论文提出新的损失函数,等等这些都要求作者具备二次开发的能力。而这些复杂的框架由于其背后复杂的封装,让非计算机系的同学往往望而却步,如果能把其背后关于深度学习神经网络的部分单独拿出来分析其背后的工作机理,那么再去看市面上这些各式各样的框架就能轻车熟路了。本框架完全基于Python和Cupy(一个矩阵运算库,Numpy的镜像,运行在GPU上的)从零开始实现神经网络框架,在这里,你将会见证如何从基础的加减乘除算子,到最后复杂的CNN,RNN模型的整个构建过程。
关于本框架Rhitta_GPU
1.环境准备:
numpy,cupy,pandas,matplotlib,sklearn这些版本随意,只要能import出来即可
对于cupy,如果import失败,请查看本框架目录下的环境配置txt文件,或者自己搜索如何安装使用cupy
2.如何使用:
把Rhitta_GPU放在D盘根目录下,可正常运行所有test和examples下的示例程序,如果放在其他目录下,框架是可以正常运行的,但是里面的示例程序需要修改一点点内容才能运行
3.本框架的底层逻辑
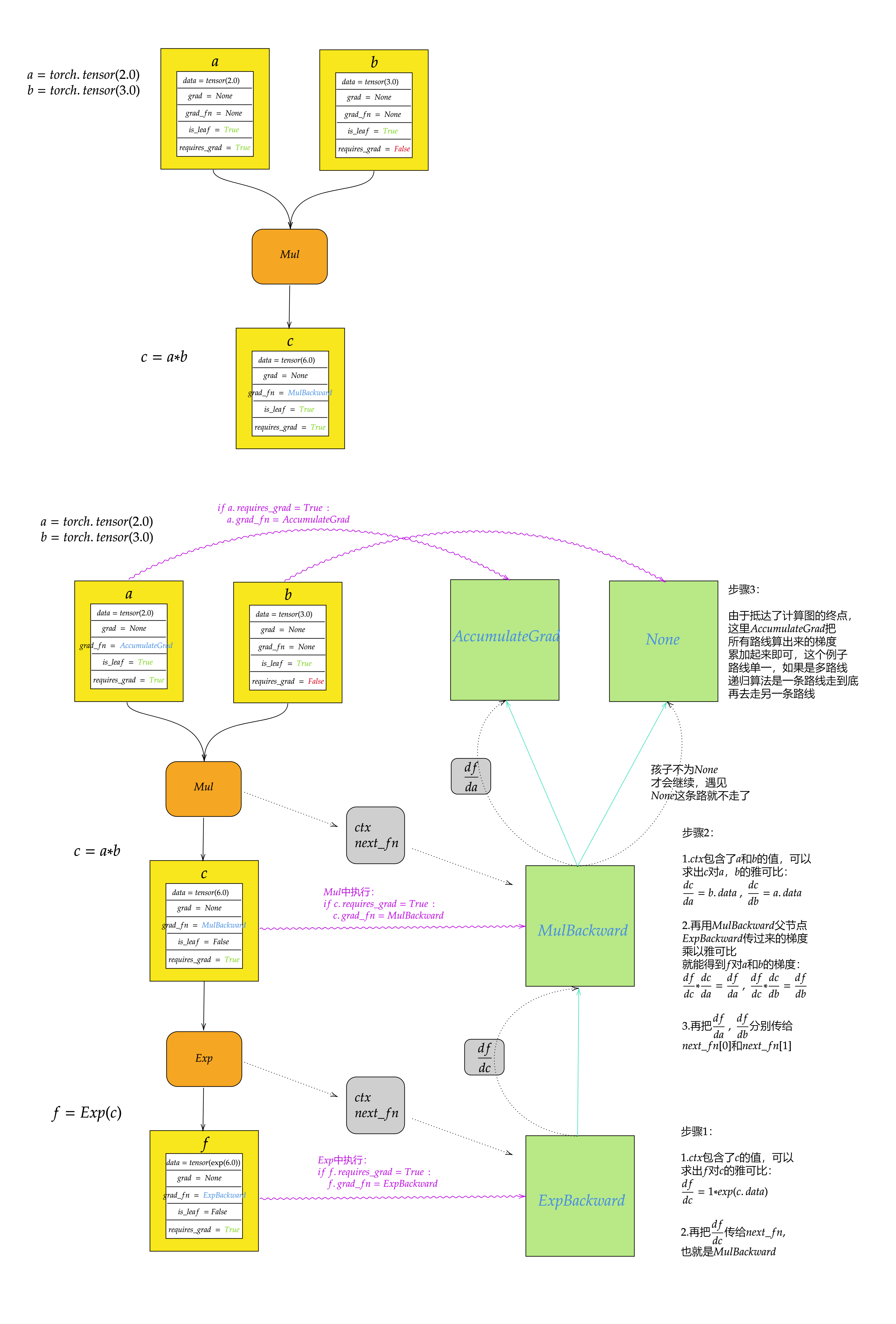
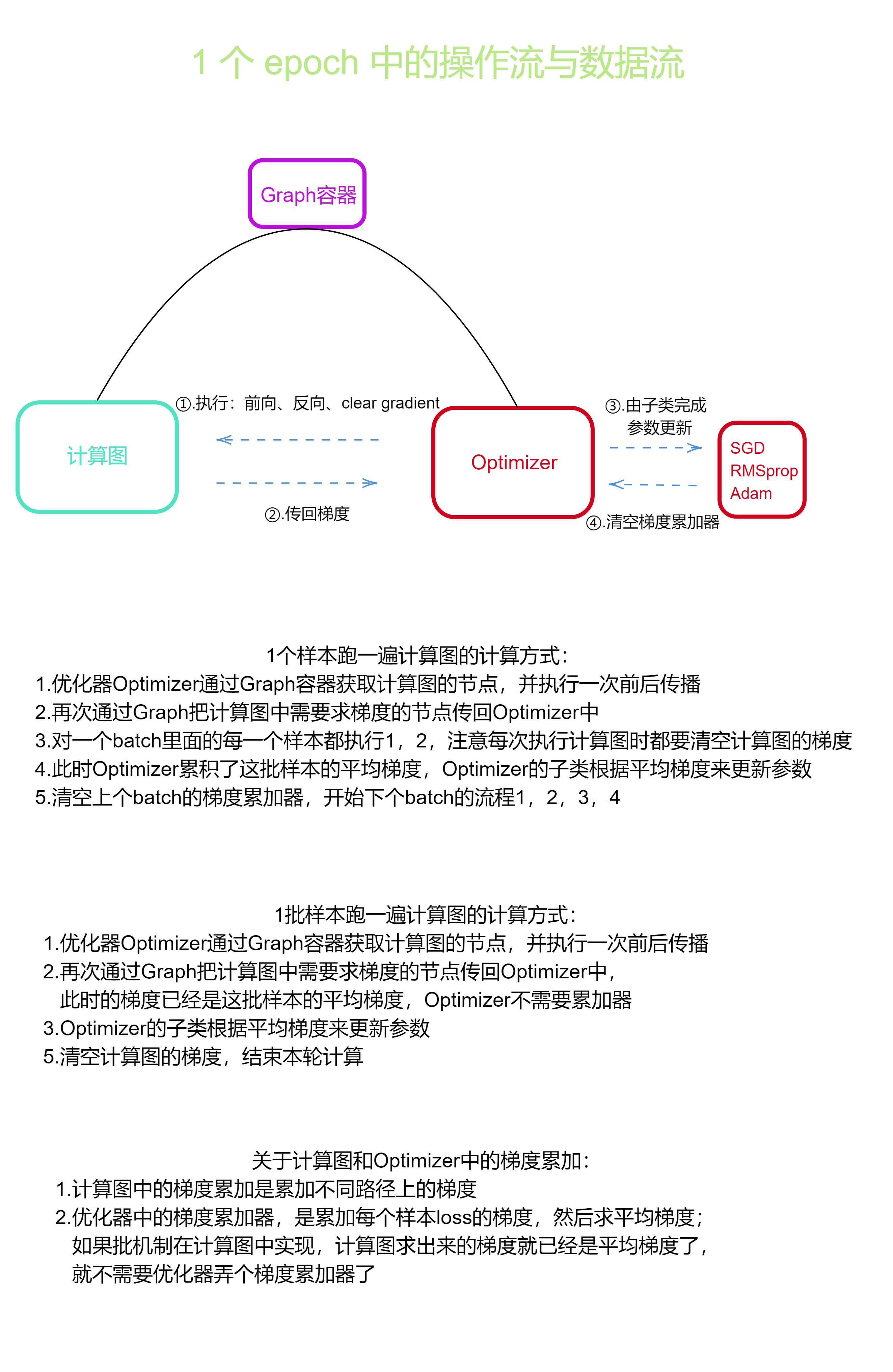
如下图,本框架采用静态图机制,使用Tensor类及其子类(各种算子)自动构建静态图,
并实现前向传播和反向传播,各个算子被容器Graph引用,Optimizer通过Graph可以
遍历计算图中的数据,并可以更新其参数。
4.本框架的缺陷
首先是静态图,灵活性低,另外前向传播和反向传播的算法效率非常低,速度很慢;
第二点就是批机制是通过for循环一个一个处理样本实现的,没有使用矩阵的并行计算;
第三点是一些基础算子没有优化,比如卷积算子,窗口滑来滑去,一个一个按顺序算,其实可以同时算的,再把同时算出来的值填到结果矩阵里,但是不是计算机系的,Python有GIL锁,另外这个是运行在cuda上面的,不会多线程或者多进程编程,速度特别慢。
总之,这是一个计算速度特别慢的框架,其意义并不在于把它当作生产力工具,而是在于从中学习其背后的工作原理。当原理掌握后,一通百通,各种框架不在话下。
5.本框架实现的主要算子
| 底层API | 中层API | Model |
|---|---|---|
| Add | Conv2D | SCN |
| Sub | Pooling | ResNet_simple |
| Matmul | ReLU | SRN |
| Multiply | Linear | LSTM |
| Div | LayerNorm | BiLSTM |
| sum | RNNCell | |
| mean | LSTMCell | |
| power | ResBlock4x4 | |
| sqrt | ResBlock4x8 | |
| Concat | ResBlock8x8 | |
| Logistic | ||
| Tanh | ||
| Softmax | ||
| Relu | ||
| BinaryClassLoss | ||
| CrossEntropyLoss | ||
| MSELoss | ||
| conv2d | ||
| MaxPooling | ||
| AveragePooling | ||
| embedding | ||
| layernorm |
6.关于计算图
自动微分算法是所有深度学习框架的核心中的核心,关于其算法,我搜集了很多经典的教程,请点击”机器学习与深度学习”一栏查找